
Não é comum termos planos para tempos de inatividade. Mesmo assim problemas são inevitáveis e, se não houverem planos para lidar com eles de maneira enérgica e automática, a perda de receita é certa quando ocorrerem quedas nos serviços oferecidos. É o momento em que a alta disponibilidade costuma ajudar no planejamento dos piores cenários.
Explicando melhor a Alta Disponibilidade:
A Alta disponibilidade (HA – High Availability) consiste na prática de minimizar todo o tempo de inatividade de um servidor, idealmente abaixo de zero. Incorpora muitas técnicas como monitoramento em tempo real, escala automática e implantações automatizadas de atualização.
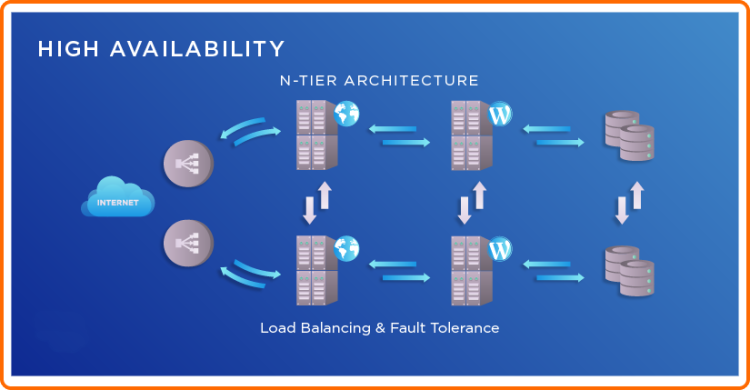
O principal conceito é muito simples considerando por exemplo que um servidor não é um servidor, dois servidores são um servidor. Quanto maior o nível de redundância é planejada então por mais tempo disponível estará o serviço. Os serviços definitivamente não devem sofrer interrupções, indiferente do nível ou abrangência da tragédia ocorrida.
Condições como essa podem ser providenciadas de maneira bem simples quanto um grupo de escala automática, serviços em nuvem como da AWS suportam muito bem. Quando o balanceador de carga perceber a indisponibilidade de um servidor, poderá redirecionar o tráfego desse servidor problemático os outros servidores no cluster (grupo de recursos, aqui sendo servidores), inclusive podendo gerar uma nova instância, se precisar da capacidade.
Representando uma filosofia redundante aplicando-se a todos os níveis da hierarquia de componentes. Num cenário onde possua micro-serviços para processamento de imagens enviadas pelo usuário por exemplo, não é uma grande ideia executá-lo em segundo plano em um dos computadores. Na condição desse computador apresentar problemas o usuário ficará impossibilitado de enviar essas imagens significando tempo de inatividade parcial do serviço e possivelmente frustrando a experiência do usuário final.
Cada vez mais é fundamental garantir essa disponibilidade aos clientes. Ao assegurar uma disponibilidade de 99,999% firmada num Acordo de Nível de Serviço (SLA – Service Level Agreement), significa que esse serviço não poder ficar indisponível por mais de cinco minutos por ano. Transformando o HA como indispensável desde o início para diversas grandes empresas.
Novamente no exemplo da AWS com o S3 vincula o SLA´s a garantir 99,99999999% (nove 9´s) de redundância de dados. De maneira geral, todos as informações são replicadas em todas as regiões do seu ambiente protegendo-os de tudo, exceto em cenários de gigantesco impacto de meteoros em seu armazém de dados. Ainda assim, com a separação física existe o resguardo contra pequenos meteoros ou no mínimo, salvos de eventos bem mais realistas como incêndio ou falta de energia no armazém de dados..
-
Pìlares para bons sistemas de HA:
Quais eventos provocam tempo de inatividade !? Excluindo-se atos divinos, os períodos de inatividade são geralmente causados por falhas aleatórias normalmente relacionadas a erros humanos em algum nível.
Embora falhas aleatórias não possam realmente ser planejadas, podem ser precavidas com sistemas redundantes. Podem também serem capturadas enquanto ocorrem com eficientes sistemas de monitoramento, emitindo alertas sobre problemas em seu ambiente.
Agora, erros humanos pode ser antecipados iniciando pela redução da quantidade de erros através de cuidadosos ambientes. Por conta da natureza humana sujeita a erros indiferente do porte da empresa, elaborar e manter um plano para quando ocorrerem é uma excelente estratégia.

-
Redundância Automática e Escalabilidade:
Entende-se como escalabilidade (ou escala automática) a capacidade de dimensionar automaticamente o número de servidores em atividade, ocorrendo para suportar altas solicitações de processamento ou nível de requisições.
Um dos principais eventos que provocam a queda dos serviços é conhecido como abraço da morte, momento onde milhares de usuários se reúnem conjuntamente no site aumentando vertiginosamente o tráfego de visitações. Sem o recurso de escalabilidade a queda é certa e questão de tempo para ocorrer, sem poder equilibrar os acessos resta apenas aguardar até a redução dessas solicitações, quando possível iniciar uma nova instância para balancear a carga.
Nunca precisar lidar com essa dificuldade é o objetivo da escala automática, ainda que esse tempo e recursos extras sejam cobrados posteriormente. De qualquer maneira, são motivos pelos quais serviços de bancos de dados sem servidor e funções Lambda da AWS são tão bons, são extremamente bem definidos.
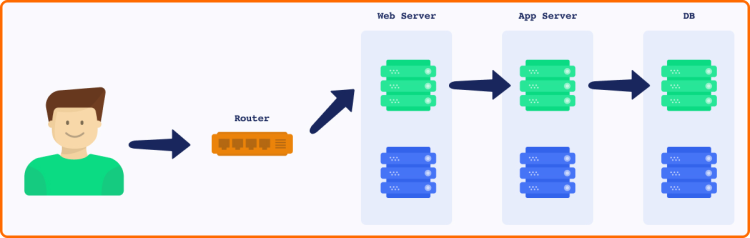
Entretanto, a escala automática vai além de servidores principais se existirem outros componentes ou serviços em seu ambiente, são componentes que também deverão ser dimensionados. Exemplificando na necessidade de disponibilizar Servidores Web adicionais para atender o alto tráfego porém se Servidor de Banco de Dados estiver sobrecarregado, outro problema estará se apresentado.

-
Serviço de Monitoramento 24/7:
A atividade de monitoramento envolve análise e acompanhamento de logs (registros de atividade) e métricas nos serviços de execução em tempo real. Executar com alarmes automáticos permite alertá-lo sobre problemas na rede enquanto ainda estão ocorrendo ao invés de informarem após afetarem os usuários.
Em exemplo, é possível definir um alarme para disparar quando um determinado servidor atingir 90% do uso de memória, possivelmente assinalando um vazamento de memória ou um problema de sobrecarga em alguma aplicação ou programa.
A seguir, configurar esse alarme para alertar a equipe de escala automática para iniciar uma nova ou substituir a instância atual por uma nova.
-
Atualizações automatizadas Azul/Verdes:
O ambiente mais comum para erros está uma atualização incorreta, na alteração do código que compromete uma parte imprevista da aplicação. Evento passível de planejamento com implantações no modelo azul/verde.
O modelo de implantação azul/verde é um processo gradual e lento implementando modificações graduais de código em vez de completas. Por exemplo, imagine tendo 10 servidores executando a mesma aplicação apoiado por balanceador de carga.
Numa implantação regular a atualização será aplicada imediatamente a todos eles assim que disponibilizadas senão atualizá-las uma por vez para evitar um possível tempo de inatividade.
Utilizando o modelo azul/verde seria incluído um 11° servidor no grupo de escalabilidade, instalando as novas alterações de código nele e dessa maneira, ao mudar para “verde” ou aceitando solicitações e pronto para uso, substituiria imediatamente um dos servidores “azuis” do grupo. Seguindo repetidamente para todos os demais servidores, praticamente zerando o tempo de indisponibilidade do ambiente.
Poder reverter imediatamente as modificações nos servidores “azuis” na identificação de problemas no sistemas, emitidos pelos alarmes de monitoramento, é outro benefício e dessa maneira, uma atualização defeituosa e capaz de inutilizar uma instância não afetará significativamente os serviços, mesmo assim por alguns minutos. As implementações azul/verde podem ser configuradas para atualizar apenas 10% dos servidores em atividade a cada 5 minutos, como exemplo promovendo uma atualização ao longo de 1 hora.
Conclusão:
A Alta Disponibilidade e Escalabilidade são os conceitos da atualidade, pela reconhecida dependência na informática de automatização além da velocidade e volume de processamento dos mais variados tipos de informação. Por conta da Alta Disponibilidade ocasionar mais vulnerabilidade para crimes digitais ela fatalmente se transforma ainda mais num contexto muito importante a ser abordado pelas empresas.
Em conjunto a isso, a Escalabilidade por conta do volume e velocidade no processamento das informações em transformação praticamente ininterruptas motivam ainda mais o entendimento e planejamento desses ambientes a qualquer corporação que pretenda disponibilizar e manter serviços tanto locais como hospedados em nuvem.
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
**********************************************************************************
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
*****************************************