 Qual a solução mais adequada: Banco de Dados Relacional ou Não Relacional ?
Qual a solução mais adequada: Banco de Dados Relacional ou Não Relacional ?
É muito bom saber que o título foi atrativo para sua curiosidade em avaliar as diferenças entre técnicas entre bancos de dados relacionais e não relacionais. Entretando antes de continuar é importante repassar esse modelo de dados no quadro brando então determinando a prioridade que a escalabilidade representa para esse modelo em particular. Faça esboços no no papel se necessário; soluções de baixa tecnologia como canetas coloridas diferentes não siginifcam qualquer tipo de limitação. A intenção é começar com uma ideia clara onde uma imagem certamente pode colaborar nessa interpretação.
Para encaixar este modelo de dados com a maior precisão possível é mandatŕio estabelecer as perguntas certas. Questões vagas ou inadequadas, não inesperadamente resultam em dados ruins ou insuficientes. Não é o resultado deseja no desenvolvimento programático do problema da vida real de alguém – independentemente de escolher um banco de dados relacional ou não relacional.
Conhecendo o modelo Bancos de dados relacionais
Bancos de dados relacionais como MySQL, PostgreSQL e SQLite3 representam e armazenam dados em tabelas e linhas. Sendo baseados em um ramo da teoria dos conjuntos algébricos conhecido como álgebra relacional. Enquanto isso, bancos de dados não relacionais como o MongoDB representam dados em coleções de documentos JSON. O utilitário de importação Mongo pode importar formatos de arquivo JSON, CSV e TSV. Os elementos de consulta de dados do Mongo são tecnicamente representados como BSON (binary JASON).
Os bancos de dados relacionais utilizam SQL (Structured Querying Language), sendo uma escolha adequada para aplicativos que envolvam o gerenciamento de várias transações. A estrutura de um banco de dados relacional permite vincular informações de diferentes tabelas por meio do uso de chaves estrangeiras (ou índices), utilizadas para identificar exclusivamente qualquer parte atômica de dados nessa tabela. Outras tabelas podem se referir a essa chave estrangeira, de modo a criar uma referência entre suas partes de dados e o objeto apontada pela chave estrangeira. Isso é útil para aplicativos pesados na análise de dados.
Se deseja que seu aplicativo lide com muitas consultas complicadas, transações de banco de dados e análise de rotina de dados, provavelmente desejará manter um banco de dados relacional. E se o seu aplicativo vai se concentrar em fazer muitas transações de banco de dados, é importante que essas transações sejam processadas de forma confiável. É nesse ponto que o ACID (o conjunto de propriedades que garantem que as transações do banco de dados são processadas de forma confiável) realmente importa e onde a integridade referencial entra em ação.
Integridade referencial (e minimização da incompatibilidade de impedância ORM)
Integridade referencial é o conceito no qual várias tabelas de banco de dados compartilham um relacionamento com base nos dados armazenados nas tabelas e esse relacionamento deve permanecer consistente. Isso geralmente é aplicado com ações em cascata de adição, exclusão e atualização. Para ilustrar um exemplo de cumprimento da integridade referencial, consideremos um aplicativo que ajude as vítimas do tráfico humano a localizar uma casa segura e acessar os serviços às vítimas em tempo real.
Suponha que a cidade ou o município X tenha duas tabelas; uma mesa de abrigo de vítimas de tráfico e uma tabela de financiamento de abrigo de tráfico. Na tabela Shelter de Tráfico, temos duas colunas; o Shelter ID (que poderia ser o seu número EIN / FEIN) e o nome do abrigo. Na tabela de financiamento do abrigo de tráfico, também temos duas colunas; o ID do abrigo e o valor do financiamento recebido pelo ID do abrigo. Agora, suponha que uma escassez de fundos forçou o abrigo A na cidade/município X a fechar suas portas. Nós precisaríamos remover esse abrigo do local X, já que ele não existe mais. E como o Shelter A também existe na tabela de financiamento do abrigo, também precisamos removê-lo de lá. Ao aplicar a integridade referencial, podemos tornar isso preciso e com o mínimo de dores de cabeça.
Veja como:
Primeiro, definindo a coluna ID do Abrigo na tabela Abrigo para a chave primária. Em seguida, definindo a coluna ID do Abrigo na tabela Financiamento do Abrigo para ser uma chave estrangeira que aponte para uma chave primária (que é a coluna ID do Abrigo na tabela Abrigo). Depois de definidos os relacionamentos de chave estrangeira para primária é preciso adicionar restrições. Uma restrição em particular é conhecida como exclusão em cascata . Isso significa que sempre que um abrigo for excluído da tabela do Abrigo em nosso banco de dados, todas as entradas desse mesmo abrigo serão removidas automaticamente da tabela de Financiamento do Abrigo.
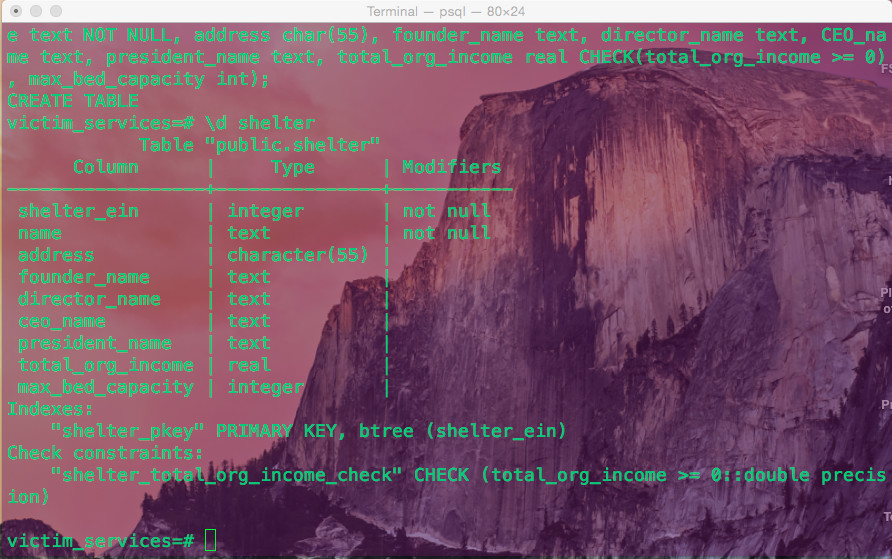
Agora anotando o que foi designado como a chave primária e por quê. Neste pequeno exemplo de instituições de caridade anti-tráfico, todas as ONGs sem fins lucrativos com o status 501 recebem um EIN, muito parecido com o número da previdência social de um indivíduo. Assim, em tabelas onde outros dados são vinculados ao abrigo de qualquer vítima de tráfico em particular na tabela de abrigo, faz sentido que esse identificador exclusivo sirva como a chave primária e que as chaves estrangeiras apontem para ele.
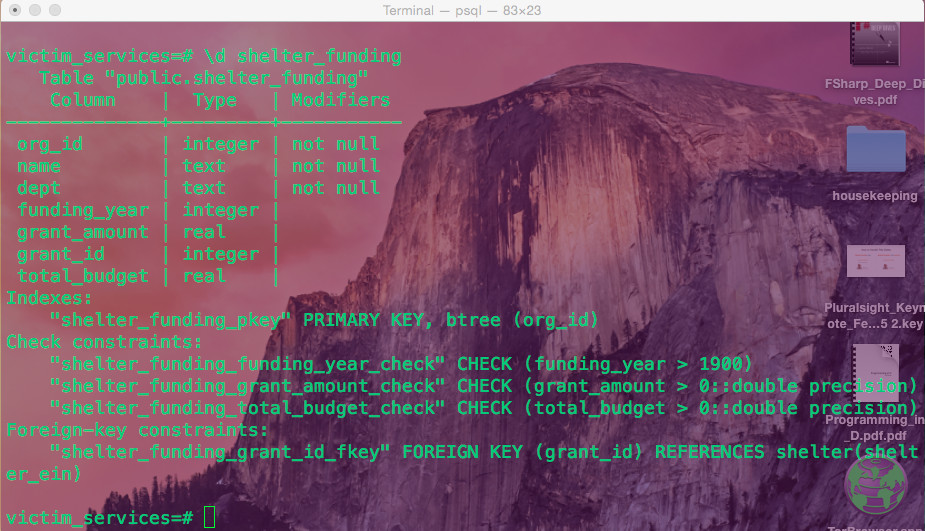
Tenha em mente a existência de três regras impostas pela integridade referencial:
-
Não é permitido adicionar um registro à tabela de financiamento do abrigo, a menos que a chave estrangeira para esse registro aponte para um abrigo existente na tabela do abrigo. Considere como uma regra de “Nenhuma criança sem supervisão” ou uma regra de “Sem órfãos”.
-
Se um registro na tabela de abrigo for excluído, todos os registros correspondentes na tabela de Financiamento do Abrigo também deverão ser excluídos. A melhor maneira de lidar com isso é usando a exclusão em cascata .
-
Se a chave primária de um registro na tabela do Abrigo for alterada, todos os registros correspondentes no Financiamento do Abrigo (e outras possíveis tabelas futuras com dados relacionados à tabela do Abrigo) também devem ser modificados usando algo chamado atualização em cascata .
O ônus de instalar e manter a integridade referencial depende da pessoa que cria o esquema do banco de dados. Se projetar um esquema de banco de dados parecer uma tarefa difícil, considere isto: Antes de 1970 (quando o banco de dados relacional nasceu), todos os bancos de dados eram planos; os dados ficaram armazenados em um arquivo de texto longo chamado de arquivo delimitado por tabulação, onde cada entrada era separada pelo caractere pipe (“|”). Buscar informações específicas para comparar e analisar era um esforço difícil, tedioso e demorado. Com os bancos de dados relacionais, é possível pesquisar, classificar e analisar facilmente (geralmente para fins de comparação com outros dados) partes específicas de dados sem precisar pesquisar sequencialmente por um arquivo inteiro (ou banco de dados), incluindo todos os dados que não esteja interessado.
No exemplo anterior de um banco de dados relacional (Postgresql), não é necessario pesquisar no banco de dados inteiro apenas para encontrar informações sobre um abrigo que teve seu financiamento reduzido ou que foi forçado a fechar por falta de fundos. Uma consulta SQL simples pode ser utilizda para encontrar quais abrigos foram fechados em uma determinada região ou localidade sem precisar percorrer todos os dados, incluindo abrigos que não estejam nessa área específica, usando uma instrução SQL SELECT * FROM.
O Recurso Object Relational Mapping (ORM) refere-se ao processo programático de conversão de dados entre sistemas de tipos incompatíveis em linguagens de programação orientadas a objetos (como Ruby).
Quando não se relacionar
Enquanto bancos de dados relacionais são excelentes, eles vêm com recursos como o Mismatching ORM Impedence, porque bancos de dados relacionais não foram desenvolvidos inicialmente com as linguagens OOP em mente. A melhor maneira de evitar esse problema é criar o esquema de banco de dados com integridade referencial em seu núcleo. Portanto, ao usar um banco de dados relacional com um OOP (como o Ruby), é fundamental pensar em como configurar suas chaves primárias e estrangeiras, o uso de restrições (incluindo a exclusão e atualização em cascata) e como você grava suas migrações.
Mas, se estiver lidando com uma quantidade fenomenalmente enorme de dados, pode ser muito cansativo e a probabilidade de erro (na forma de um problema de Incompatibilidade de Impedância de ORM) aumenta. Nessa situação é interessante considerar ir com um banco de dados não relacional. Um banco de dados não relacional apenas armazena dados sem mecanismos explícitos e estruturados para vincular dados de diferentes tabelas (ou buckets) entre si.
O Mongo é um banco de dados não-relacional popular para desenvolvedores de pilha do MongoDB Ember Angular e Node.js (MEAN) porque é basicamente escrito em JavaScript; JSON é JavaScript Object Notation sendo um formato leve de intercâmbio de dados. Se o modelo de dados for muito complexo ou se precisar desnormalizar o esquema de banco de dados, bancos de dados não relacionais como o Mongo podem ser o melhor caminho a percorrer. Outras razões para escolher um banco de dados não relacional incluem:
-
A necessidade de armazenar matrizes serializadas em objetos JSON
-
Armazenando registros na mesma coleção que possuem diferentes campos ou atributos
-
Descobrir-se desnormalizando seu esquema de banco de dados ou codificando problemas de desempenho e escalabilidade horizontal
-
Problemas que pré-definem facilmente o esquema devido à natureza de seu modelo de dados
Suponha o desenvolvimento de um aplicativo e neste exemplo para as câmaras seguras de vítimas de tráfico era parte de um modelo de dados que era muito complexo e tinha muitas tabelas, tornando a integridade referencial extremamente difícil. Para lidar com a representação das ONGs fornecedoras de serviços de vítimas de tráfico como esta, utilizando o Mongo:
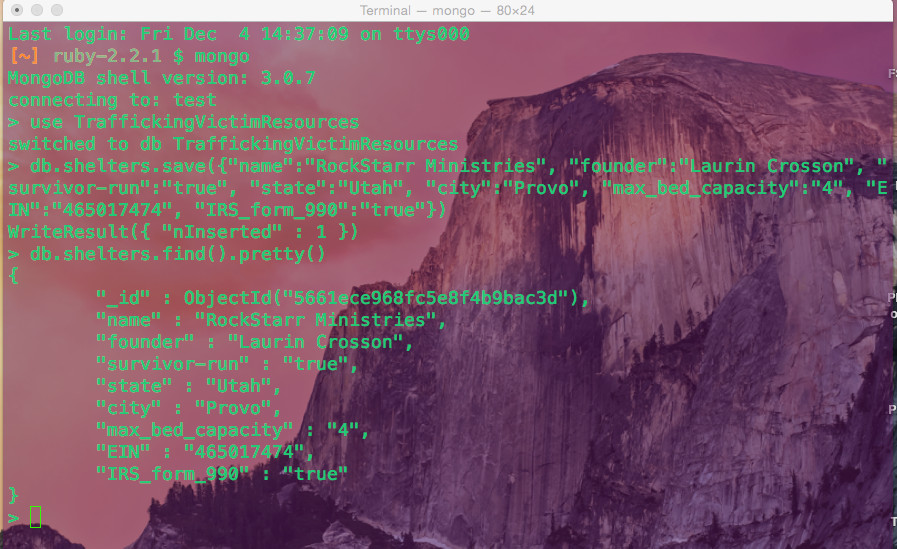
Observe o resultado de fácil leitura. O Mongo sendo acessível com JavaScript e do ponto de vista do desenvolvedor MEAN stack, não faria sentido ir com qualquer banco de dados que não fosse facilmente acessível. Além disso o site MongoDB está bem documentado, fornecendo exemplos claros e concisos de como configurar um banco de dados Mongo e aproveitá-lo ao máximo. Como um banco de dados NoSQL, o MongoDB permite que os desenvolvedores definam o fluxo do aplicativo inteiramente no lado do código. Um dos maiores problemas que os desenvolvedores de pilhas MEAN têm com bancos de dados relacionais é o fato inevitável de que os objetos representados no banco de dados serem armazenados em um formato que não pode ser facilmente usado pelo frontend e vice-versa.
Mas não são apenas os desenvolvedores de pilha MEAN que decidiram quanto a um banco de dados não relacional ser o melhor caminho a percorrer. Steve Klabnik (um membro bem conhecido da comunidade Ruby/Ruby on Rails e o mantenedor do projeto de código aberto Hackety-Hack) também escolheu o MongoDB. Claro, ele teve que fazer concessões para seguir esse caminho. Isso incluiu a dificuldade em fazer com que a refatoração Hackety-Hack fosse configurada para autenticação do usuário com contas do Facebook, Twitter, Linkedin e Github. Mas outros desenvolvedores do Rails também gostam do Mongo por sua escalabilidade horizontal superior.
Uma das maiores vantagens de usar um banco de dados não relacional é que seu banco de dados não corre o risco de ataques de injeção de SQL, porque os bancos de dados não relacionais não usam SQL e, na maioria das vezes, são sem esquema. Outra grande vantagem, pelo menos com o Mongo, é teoricamente poder ser fragmentado para sempre (embora isso traga problemas de replicação). O sharding distribui os dados entre as partições para superar as limitações de hardware.
Desvantagens do banco de dados não relacional
Em bancos de dados não relacionais como o Mongo, não há junções como em bancos de dados relacionais. Isso significa que ser preciso executar várias consultas e unir os dados manualmente em seu código – e isso pode ficar muito feio, muito rápido.
Como o Mongo não trata automaticamente as operações como transações da mesma forma que um banco de dados relacional, é necessário escolher manualmente criando uma transação e em seguida, verificar manualmente, confirmar ou retroceder manualmente. Até mesmo a documentação no site do MongoDB avisa que, sem tomar algumas precauções potencialmente demoradas e como os documentos podem ser bastante complexos e aninhados, o sucesso ou a falha de uma operação de banco de dados pode ser tudo ou nada. Para simplificar, algumas operações serão bem sucedidas enquanto outras falham.
Claro, isso tudo nos traz de volta ao começo; saber como fazer exatamente as perguntas certas para poder utilizar o seu modelo de dados com eficácia. É este passo fundamental que lhe permitirá determinar a melhor rota em relação ao fluxo da sua aplicação. Dedicar um tempo para identificar as perguntas certas servirá como um guia sólido ao escolher a linguagem de programação para escrever seu aplicativo e o uso de um banco de dados específico em detrimento de outro.
Conclusão
Embora uma unanimidade quando o assunto é preservar informações para os mais variados fins, mesmo os bancos de dados tem apresentado necessidade constante de evolução pois as manipulações desses dados ocorrem das mais incontáveis maneiras, maior ainda a dinâmica quando o ambiente é constituído dos tipos de arquietura.
Por esta razão é indispensável considerar além dos conhecimentos na definição do melhor SGBD senão a utilização das duas soluções, um integrante que permita sua preservação e quando necessário, a restauração total ou parcial dos arquivos de dados principalmente pelos perigos oriundos quando precisam ficar disponíveis, progetidos por poucas camadas de isolamento como a propria aplicação onde ele éstá relacionado ou a hospedagem onde é mantido.
A Iperirus oferece uma ótima gama de soluções para preservação, replicação e restauração não somente das bases de dados como todo o ambiente na plataforma Windows, conheça hoje mesmo todo o portifólio de produtos Iperius e escolha a melhor solução para o seu ambiente.
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
**********************************************************************************
PLEASE NOTE: if you need technical support or have any sales or technical question, don't use comments. Instead open a TICKET here: https://www.iperiusbackup.com/contact.aspx
*****************************************